从零开始,构建你的第一个Scrapy爬虫项目
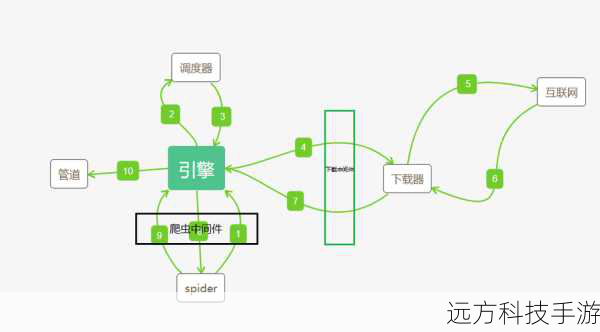
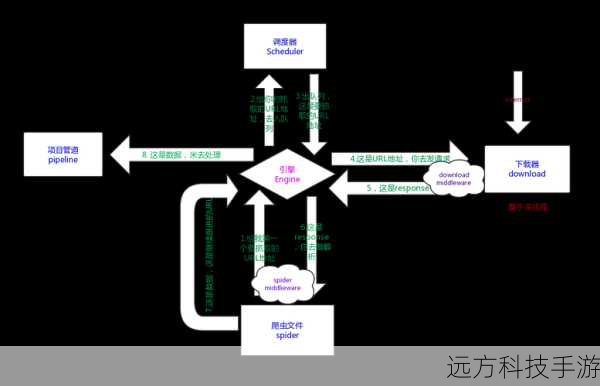
构建一个Scrapy爬虫项目,从零开始是一个充满学习与实践的过程。你需要安装Python环境,确保Python版本为3.x。然后通过pip工具安装Scrapy框架,命令为pip install scrapy。创建一个新的项目,使用命令scrapy startproject my_spider(将my_spider替换为你的项目名)。进入新创建的项目目录,使用scrapy genspider example example.com(将example和example.com替换为你想要爬取的网站)来生成一个基本的爬虫脚本。,,在生成的爬虫脚本中,你可以定义请求URL、解析规则以及数据提取逻辑。Scrapy提供了强大的XPath和CSS选择器来帮助你从HTML页面中提取所需信息。别忘了配置settings.py文件以设置各种参数,如下载延迟、重试次数等。,,在编写爬虫时,遵循网站的robots.txt规则,并考虑使用Scrapy的中间件来处理如cookies、代理、请求头等高级功能。运行爬虫,确保一切按预期工作。这可能需要调整一些设置或解析规则,直到你的爬虫能够稳定、高效地抓取目标网站的数据。,,这个过程不仅能够帮助你收集所需的信息,还能够提升你的编程技巧,尤其是对于Web爬虫技术的理解。记得在实际应用中尊重网站的使用条款和版权,合理合法地使用爬虫技术。
在这个充满数据的数字时代,我们经常需要从互联网上抓取大量的信息,Scrapy是一个强大的Python库,可以帮助我们自动化这一过程,轻松地抓取网站数据,如果你对网络爬虫感兴趣,或者想要为你的自媒体项目增加更多数据驱动的功能,那么学习如何使用Scrapy就变得尤为重要了,下面,我将引导你从零开始构建自己的第一个Scrapy爬虫项目,让你能够自信地在Python中进行网络数据抓取。

第一步:安装Scrapy
确保你的开发环境已经安装了Python,通过pip安装Scrapy,这是Python的一个包管理器,打开命令行终端,运行以下命令:
pip install scrapy
第二步:创建Scrapy项目
在你的项目文件夹内,使用Scrapy提供的命令来初始化一个新的项目:
scrapy startproject my_spider_project
这将会在当前目录下创建一个名为my_spider_project的新文件夹,其中包含了基本的项目结构和配置文件。
第三步:编写爬虫脚本
在my_spider_project目录下,你会看到一个名为spiders的文件夹,我们将创建我们的第一个爬虫脚本,打开一个文本编辑器,如VSCode或Sublime Text,创建一个新的Python文件,命名为my_first_spider.py,在文件中添加以下代码:
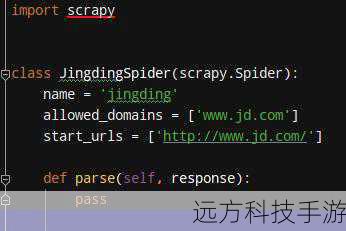
import scrapy
class MyFirstSpider(scrapy.Spider):
name = 'my_first_spider'
start_urls = ['http://example.com']
def parse(self, response):
for item in response.css('div.item'):
yield {
'title': item.css('h2::text').get(),
'description': item.css('p::text').get()
}这段代码定义了一个简单的爬虫,它从http://example.com开始抓取页面上的特定元素(在这个例子中是包含标题和描述的div标签),确保替换http://example.com和CSS选择器以匹配你想要抓取的实际网站。

第四步:运行爬虫
在my_spider_project目录下,运行爬虫:
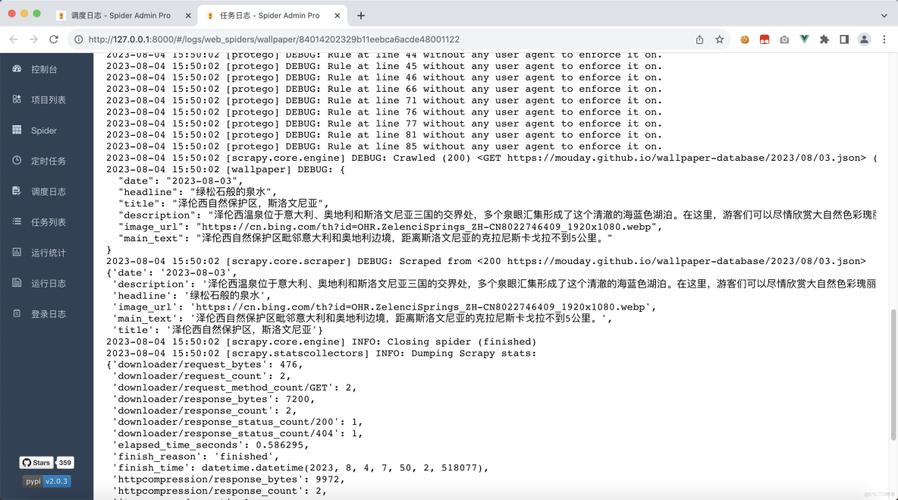
cd my_spider_project scrapy crawl my_first_spider
这将开始执行爬虫并输出结果到控制台,Scrapy会在logs文件夹下生成日志文件,记录爬虫运行过程中的详细信息。
第五步:处理和存储数据
Scrapy提供了多种方式来处理抓取到的数据,例如直接输出到控制台、保存到本地文件或发送到数据库等,你可以通过修改parse方法中的逻辑来自定义数据处理流程。
问题解答

问题1:如何避免被目标网站封禁?
为了减少被网站封禁的风险,你可以采取以下策略:
- 使用代理服务器或IP池来隐藏你的IP地址。
- 控制爬取速度,避免过于频繁的请求。
- 尊重网站的robots.txt规则。

问题2:如何处理网站动态加载的内容?
对于动态加载的内容,你可以利用Scrapy的Selenium或Splash中间件来模拟浏览器行为,抓取这些内容,这样,你可以确保抓取到最新的数据。
问题3:如何优化爬虫性能?

优化爬虫性能的方法包括:
- 并发请求:使用Scrapy的并发爬取功能,可以同时抓取多个页面,提高效率。
- 缓存机制:合理使用Scrapy的缓存系统,避免重复抓取已抓取过的页面。

- 优化代码逻辑:精简不必要的操作,提高代码执行效率。
通过以上步骤和问题解答,你应该已经对如何使用Scrapy构建爬虫有了基本的理解和实践能力,网络爬虫技术需要在遵守法律和道德规范的前提下使用,尊重网站的版权和隐私权。
